简介:
不想通过kafka shell来管理kafka已创建的topic信息,想通过管理页面来统一管理和查看kafka集群。所以选择了大部分人使用的kafka manager,我一共有一台主机master和三台节点slave1,slave2,slave3,一共有三个zookeeper server和三个kafka broker,分别在master,slave1,slave2。所以我把kafka manager安装在了slave3的服务器上面。
一、启动kafka的JMX端口的访问
至于JMX是什么,可以自己百度一下。启动JMX主要是为了kafka manger可以通过JMX端口来监听kafka的状态等。kafka启动的时候是没有启动JMX的,所以需要去修改kafka的启动脚本,来使kafka启动的时候启动JMX。
[root@master ~]# cd /usr/hdp/current/kafka-broker/bin/[root@master ~]# vi kafka-server-start.sh#添加下面标红的代码到指定位置if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G" export JMX_PORT="9999" fi
上面的操作需要在三台kafka集群上都要操作,修改完以后通过页面,重启所有的kafka集群。然后再到master,slave1,slave2上查看9999端口是否启用
[root@master bin]# lsof -i:9999COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAMEjava 55123 kafka 90u IPv6 76911524 0t0 TCP *:distinct (LISTEN)
二、安装kafka manager
1、安装sbt编译环境
[root@master ~]# curl https://bintray.com/sbt/rpm/rpm |tee /etc/yum.repos.d/bintray-sbt-rpm.repo[root@master ~]# yum install sbt
2、下载kafka-manager
访问网址下载最新版的kafka-manager,然后解压、编译。
[root@slave3 ~]# cd kafka-manager-1.3.3.17[root@slave3 kafka-manager-1.3.3.17]# sbt clean dist
编译完以后,生成的包会在kafka-manager/target/universal 下面。生成的包只需要java环境就可以运行了,在部署的机器上不需要安装sbt。
3、复制编译好的压缩包,在需要部署的kafka机器上解压即可
[root@slave3 kafka-manager-1.3.3.17]# cp target/universal/kafka-manager-1.3.3.17.zip /usr/hdp/2.6.3.0-235/[root@slave3 kafka-manager-1.3.3.17]# cd /usr/hdp/2.6.3.0-235/[root@slave3 2.6.3.0-235]# unzip kafka-manager-1.3.3.17.zip
4、修改application.conf,把kafka-manager.zkhosts改为自己的zookeeper服务器地址
[root@slave3 2.6.3.0-235]# cd kafka-manager-1.3.3.17[root@slave3 kafka-manager-1.3.3.17]# vi conf/application.conf#修改的代码kafka-manager.zkhosts="master:2181,slave1:2181,slave2:2181"
5、启动
[root@slave3 kafka-manager-1.3.3.17]# nohup bin/kafka-manager -Dconfig.file=conf/application.conf &
默认http端口是9000,可以通过命令行参数传递:./kafka-manager -Dhttp.port=9001
6、访问
访问地址 http://slave3:9000
创建kafka集群的名称,点击Add Cluster来进行创建,cluster name为kafka集群的别名自定义,zookeeper hosts填写master:2181,slave1:2181,slave2:2181。kafka version选择ambari版本里面相应的kafka版本。勾选具体配置是除开JMX with SSL不勾选,其余的全部勾选。
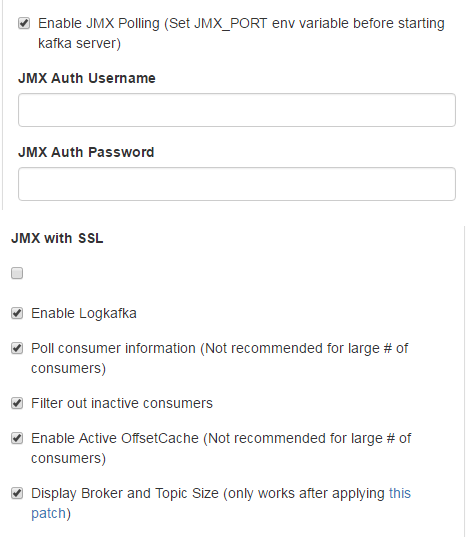
然后点击save就可以了。
7、在kafka manager里面删除topic的时候发现删除不了,但是topic的名称变成了红色。然后我修改了ambari里面kafka的delete.topic.enable的参数为true。然后就可以正常的删除topic了。至于刚才的还是红色test已经没法删除了,参考 https://blog.csdn.net/fengzheku/article/details/50585972 来对zookeeper上面的数据进行删除就可以了。